- Built on LangGraph - Simple and configurable
- Users can bring their own models, search tools, and MCP servers
- Open source implementation available on GitHub
- Try it out on Open Agent Platform
Agents are well suited to research because they can flexibly apply different strategies, using intermediate results to guide exploration.
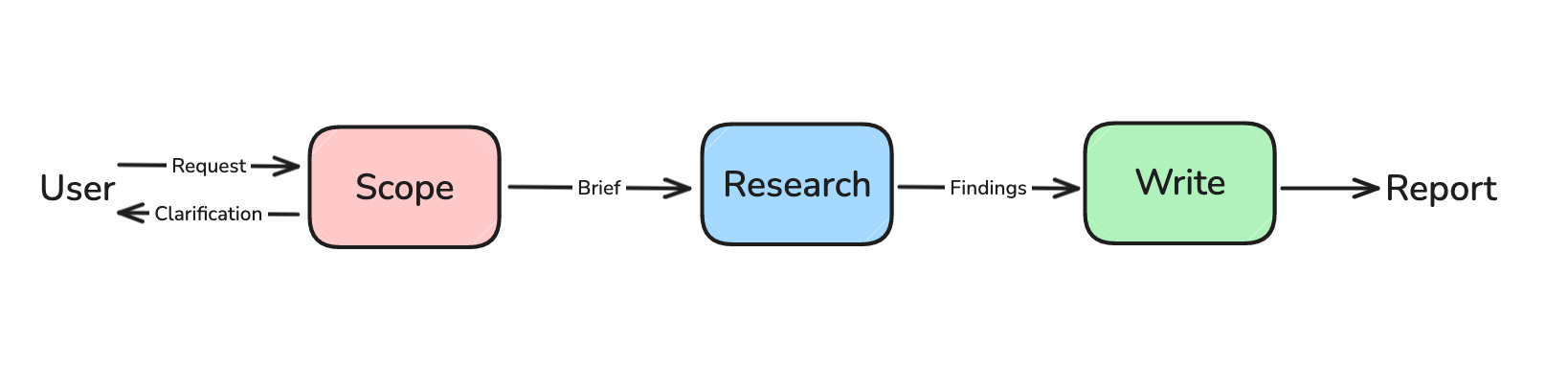
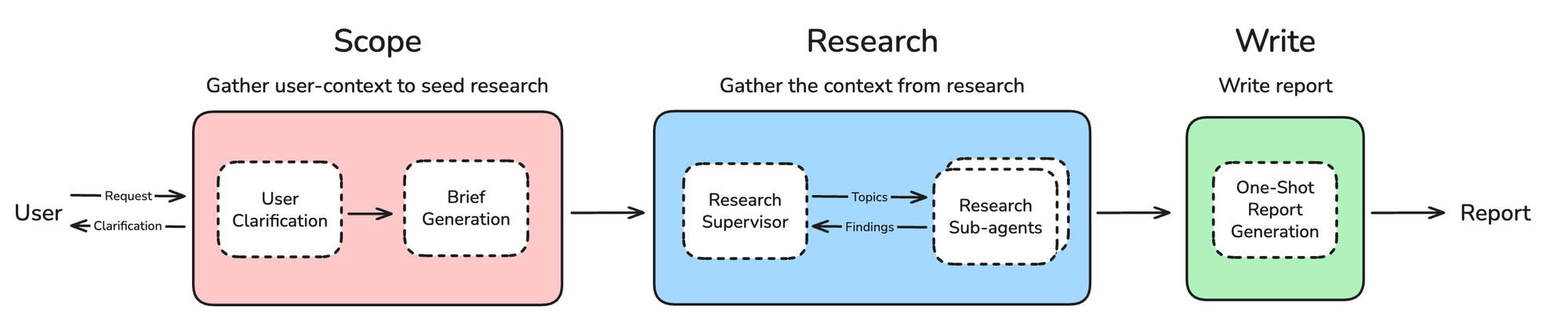
- Scope – clarify research scope
- Research – perform research
- Write – produce the final report
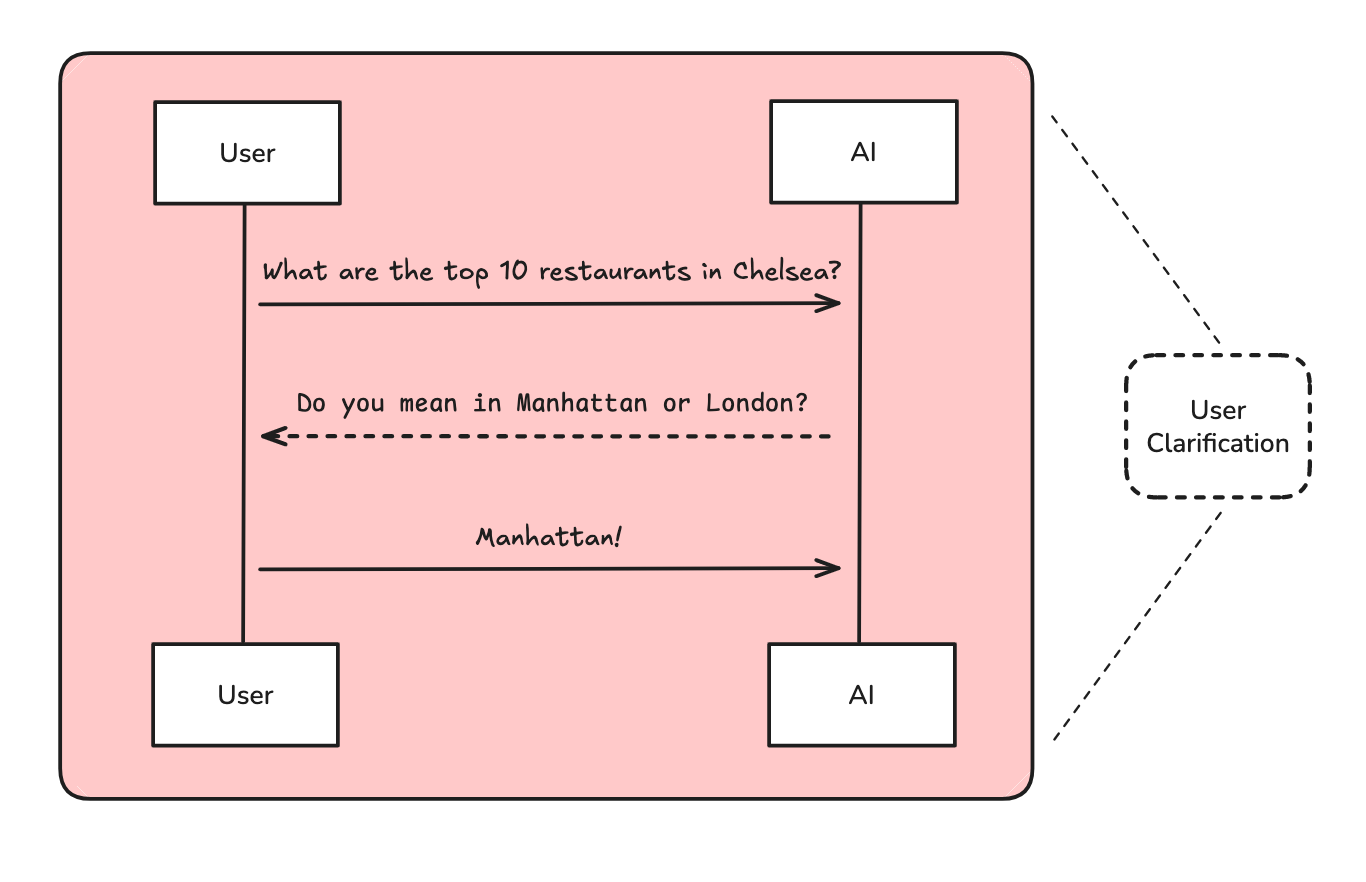
User Clarification
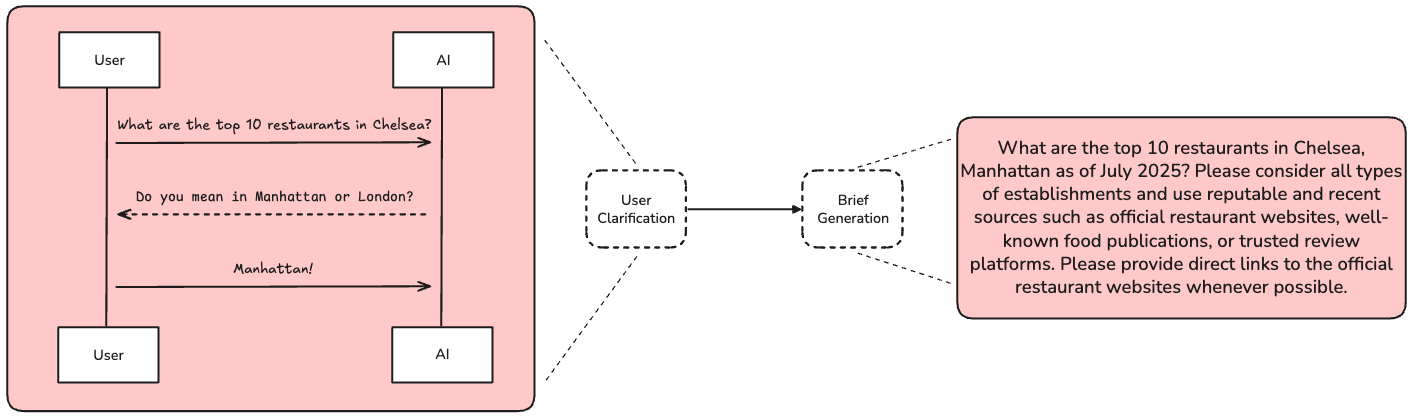
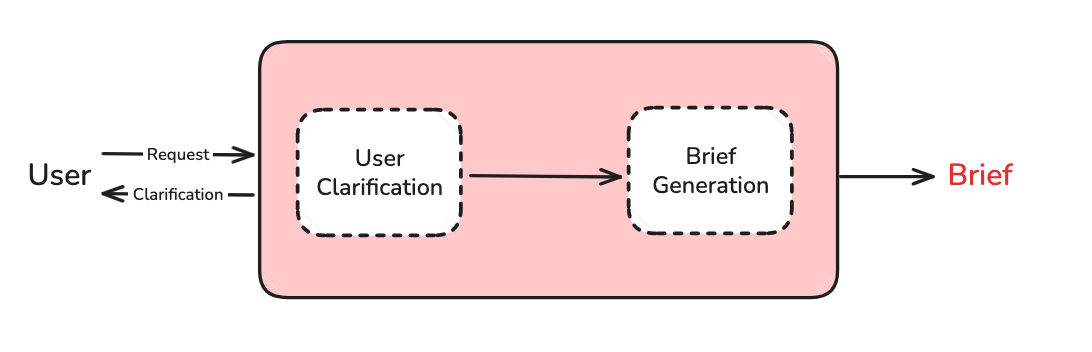
Users rarely provide sufficient context in a research request. We use a chat model to ask for additional context if necessary.
Brief Generation
We translate the verbose chat interaction into a comprehensive, yet focused research brief that serves as our north star for success.
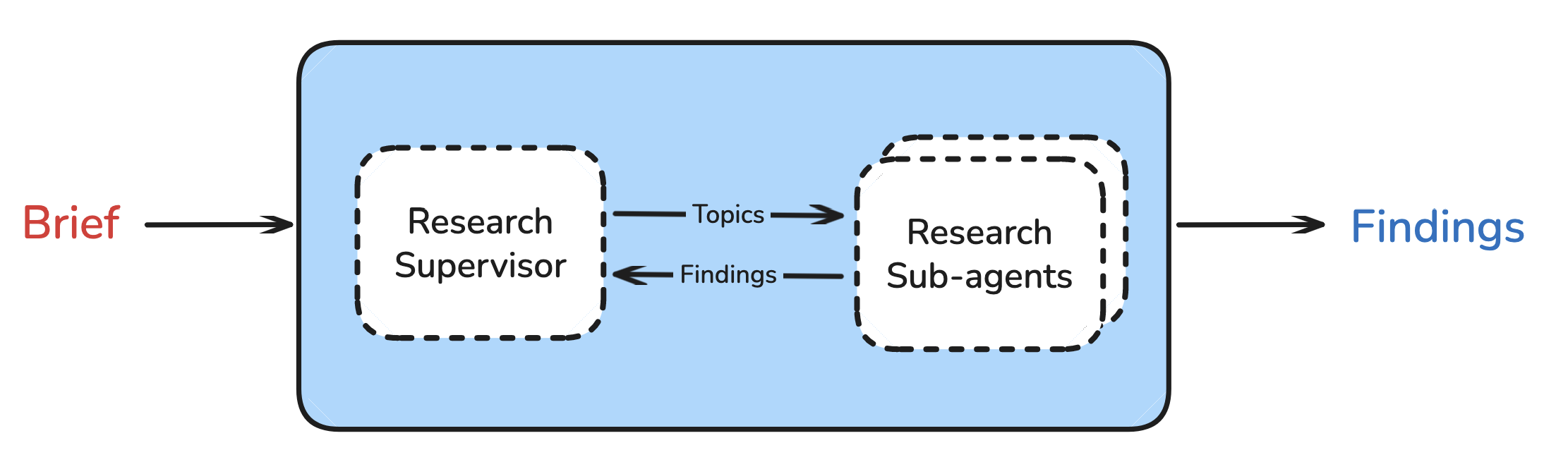
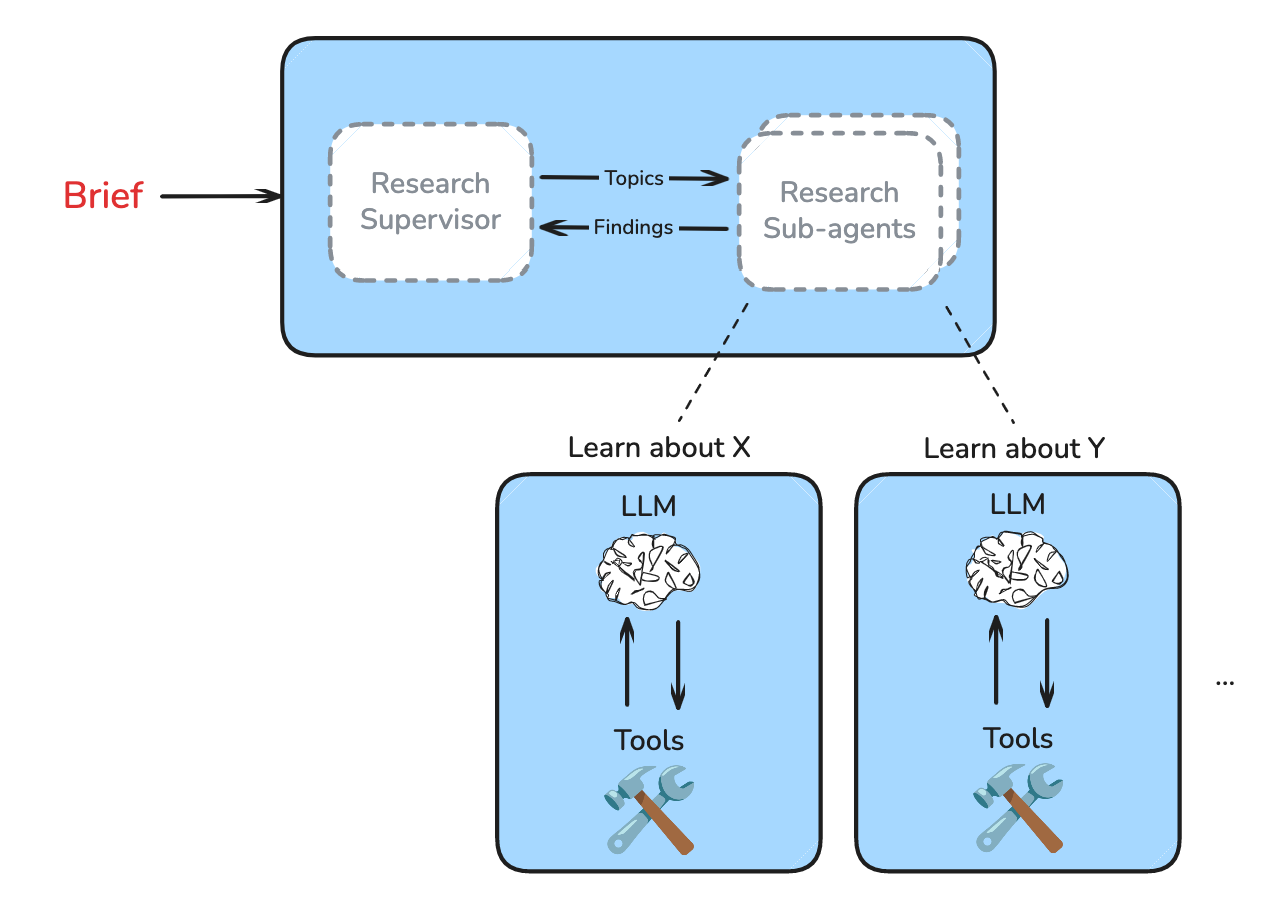
Research Supervisor
The supervisor delegates research tasks to an appropriate number of sub-agents. It determines if the research brief can be broken down into independent sub-topics and delegates to sub-agents with isolated context windows.
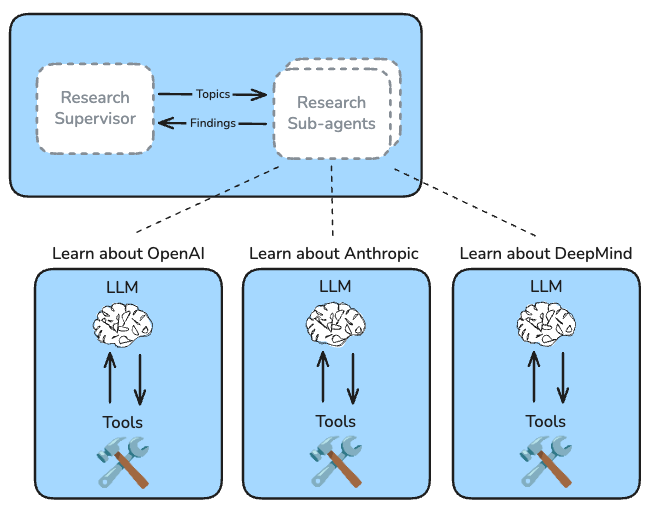
Research Sub-Agents
Each sub-agent focuses on a specific topic and conducts research as a tool-calling loop, using search tools and/or MCP tools configured by the user.
The goal of report writing is to fulfill the request in the research brief using the gathered context from sub-agents.
When the supervisor deems that the gathered findings are sufficient to address the request in the research brief, we move ahead to write the report.
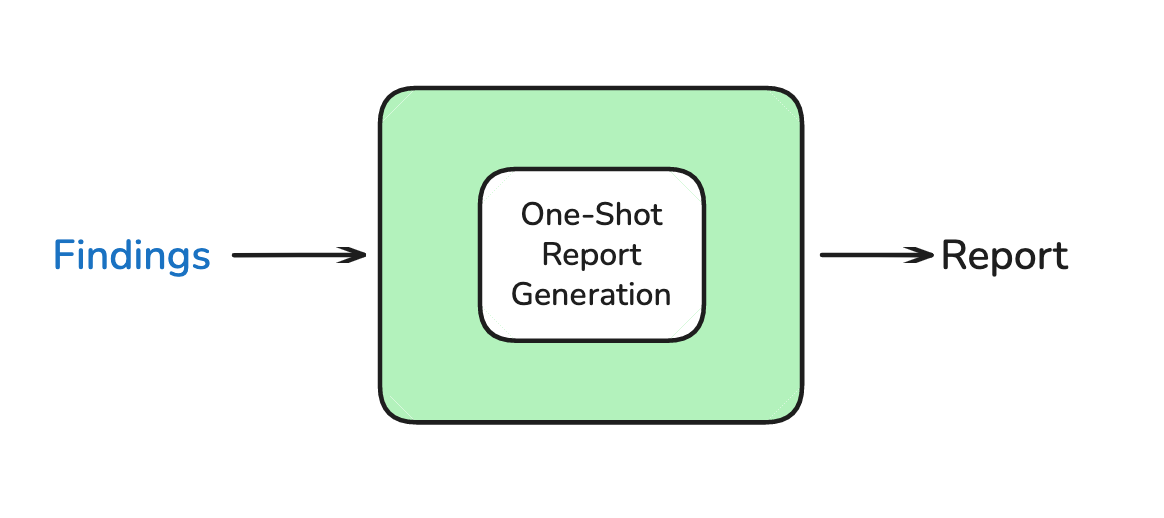
To write the report, we provide an LLM with the research brief and all of the research findings returned by sub-agents. This final LLM call produces an output in one-shot, steered by the brief and answered with the research findings.
Multi-agent is useful for isolating context across sub-research topics
Single agent response quality suffers if the request has multiple sub-topics. The intuition is straightforward: a single context window needs to store and reason about tool feedback across all sub-topics.
Our single agent implementation used its search tool to send separate queries about each frontier lab at the same time, but had to juggle context from three independent threads.
Multi-agent supervisor enables the system to tune to required research depth
Users do not want simple requests to take 10+ minutes. But, there are some requests that require research with higher token utilization and latency.
The supervisor can handle both cases by selectively spawning sub-agents to tune the level of research depth needed for a request. The supervisor is prompted with heuristics to reason about when research should be parallelized, and when a single thread of research is sufficient.
Open deep research is a living project and we have several ideas we want to try. These are some of the open questions that we're thinking about:
- What is the best way to handle token-heavy tool responses, and what is the best way to filter out irrelevant context to reduce unnecessary token expenditure?
- Are there any evaluations worth running in the hot path of the agent to ensure high quality responses?
- Deep research reports are valuable and relatively expensive to create, can we store this work and leverage these in the future with long-term memory?